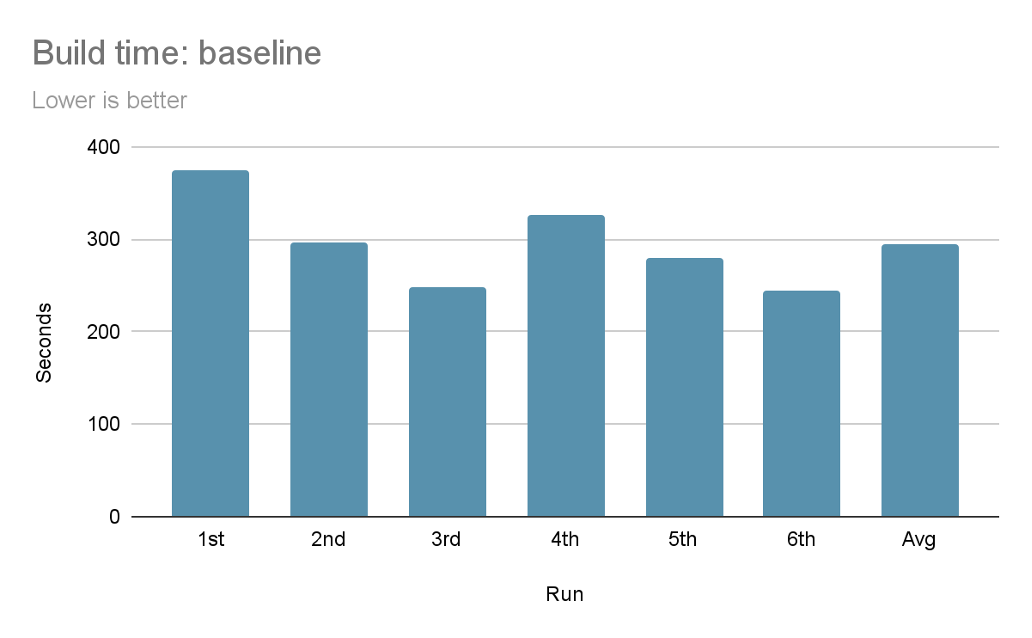
It’s clear that we have to look closer at Kotlin related tasks now.
You can see the familiar compilation and dex phrase across the tasks. If your eyes are sharp enough you can see the not-so-familiar kapt related tasks.
Kapt: annotation processing in Kotlin land
What is kapt? Well, in our opinion, out of all modules in the Kotlin eco-system, kapt must be the most hacky one in there: it was invented to run Java annotation processors on Kotlin code. If you are not familiar with annotation processing, it’s a piece of code that runs in compile time, usually to generate new code into the compilation process. It’s widely used in libraries like Dagger, Room, etc.
In Java land, the annotation processors run inside the javac process. However, Kotlin has its own compiler: kotlinc. The Kotlin compiler could have implemented the annotation processing (JSR-269) from scratch, but in the end Jetbrains people chose not to reimplement the wheel. Instead, the Kotlin compiler would generate dumb Java classes (stubs) from the Kotlin files, then use javac to run annotation processors on these stubs. Jetbrain has published an article explaining how kapt works: https://blog.jetbrains.com/kotlin/2015/06/better-annotation-processing-supporting-stubs-in-kapt/.
It seems to us that these processes are pretty wasteful: even without reading into the details you would have guessed the amount of work the compiler has to do, given the size of the codebase.
Is there any alternative to kapt? Indeed there is…
Entering ksp: the modern symbol processor for Kotlin
It turns out Google has developed a new tool called KSP that hooks directly into the Kotlin compiling process. This native Kotlin solution allows the code generator to run more efficiently without going through the hoops of the Java annotation processors. Details can be found here: https://kotlinlang.org/docs/ksp-why-ksp.html.
While it’s a sound solution, it comes with a major drawback: it’s not compatible with the existing Java annotation processing libraries. The reason is obvious: it’s a native Kotlin plugin that only handles Kotlin code. This drawback means that for every Java annotation processor library out there, they have to re-implement it in KSP. This official page lists the support status of commonly used libraries. The most famous libraries on the unsupported list as of today are probably Dagger and Hilt: the widely used dependency injection framework for Android. So if your project is using one of these two, you are out of luck, and may stop here.
Luckily for us, we don’t have any major roadblock to migrate to KSP. The frameworks/libraries that use annotation processors for our projects are:
● Moshi codegen
● Android databinding
Moshi codegen supports KSP so there’s no problem there. Now with data binding: it doesn’t support KSP and we don’t think it will ever do.
Android data binding: demon or a blessing?
When data binding was out, it was such a breath of fresh air: Android land has long suffered from the lack of a solution for binding UI. With databinding, everything binds automatically, lifecycles handled smoothly. However, we quickly discovered the drawbacks of this framework.
The ability to write full Java code in the XML is bad
As Android devs, we all learn about architectures like MVP, MVVM: one of the core ideas is to separate business/UI logic out of the View layer. Take MVVM as an example, you would have your UI logic in the ViewModel: when to show/hide a text, etc. Data binding is an excellent tool to reduce the boilerplate in this regard: you tell the View to bind to a property from the ViewModel then the data binding will update the view whenever the property value changes. It also works for the reverse: for any event from the View, you can instruct databinding to notify the ViewModel.
So far so good, until you learn that you can write the binding expression in full Java syntax, you start seeing code like this in the codebase:
<TextView
android:id="@+id/shown_price"
style="@style/BigPrice"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@{state.shownPrice}"
tools:text="$420.00"
android:visibility="@{state.shownPrice != null}"
app:layout_constraintTop_toBottomOf="@id/kf_logo"
app:layout_constraintStart_toStartOf="parent" />
It looks so innocent on the surface. But the simple line of
android:visibility="@{state.shownPrice != null}"
leaks UI logic or even business logic into the view layer: the view now decides when to show itself. What if we would like to only show the price if the price is 0, not null? That surely is a business decision and it belongs in the ViewModel. The better version is to create another property in the state called shownPriceVisibility and bind it directly here, then have the ViewModel to control this property.
One may argue that it’s not databinding’s fault to provide the ability to write full expression, at the end of the day, it’s just a tool, the users of the tool should take their own responsibility. It’s true to some extent, however, data binding provides such an easy way to manipulate the View, you’re more likely to write the seemingly small but harmful things like this. One thing we learn from the past is that, in the long run, a tool that makes it hard to misuse is miles better than the tool that does everything easily, including shooting yourself in the foot.[1]
Spotty IDE support
Have you ever had the problem that Android Studio tells you all the code referencing the XML binding is wrong but when you compile the project nothing is wrong? Then it comes with rebuilding, restarting the IDE, clearing the IDE cache and enduring the dreadful wait just to find out it doesn’t work, then all of sudden it works again. You are not alone. The team at Google and Jetbrains worked incredibly hard to fix this and you seldom see them today. It’s no one’s fault this doesn’t work seamlessly because the code generation here is so complicated: essentially you try to reference code that hasn’t been generated yet.
With databinding’s support for customized binding, it’s difficult to reason about the code: you would need to jump between Kotlin and XML files to find out where a particular binding method is written.
At last, it uses annotation processing
Needless to say, with Kotlin as our primary programming language, the use of any annotation processing library is going to slow us down.
Remove data binding
We had explained why we didn’t like data binding, in the end, our team decided to go ahead with removing data binding from our codebase. However, there’s one part of data binding we want to keep: view binding.
View binding to the rescue
If you haven’t used it before, view binding generates holder classes in Java for each XML, they expose the views as properties in the holder classes that allow you to access them directly from code. View binding used to be part of the data binding, but engineers at Google have extracted it out as a separate Gradle task. If you only enable view binding, it doesn’t involve the annotation processing as it merely transforms XML to Java, hence no need to run within the Java compilation process. This dedicated gradle task enables gradle to optimize the build process: in theory gradle can look at the input and output and figure out what has changed and what can be cached. This is not easily doable with annotation processing.
Anyway, with the help of view binding, we can transform the existing data binding XML from:
<TextView
android:id="@+id/product_name_tv"
style="?textAppearanceTitleSmall"
android:layout_width="0dp"
android:layout_height="wrap_content"
android:layout_marginEnd="16dp"
android:text="@{viewModel.title}"
app:layout_constraintEnd_toStartOf="@+id/chevron"
app:layout_constraintStart_toEndOf="@id/iv_item_image"
app:layout_constraintTop_toTopOf="@id/iv_item_image" />
To:
XML:
<TextView
android:id="@+id/product_name_tv"
style="?textAppearanceTitleSmall"
android:layout_width="0dp"
android:layout_height="wrap_content"
android:layout_marginEnd="16dp"
app:layout_constraintEnd_toStartOf="@+id/chevron"
app:layout_constraintStart_toEndOf="@id/iv_item_image"
app:layout_constraintTop_toTopOf="@id/iv_item_image" />
Kotlin:
val binding = ProductItemViewBinding.inflate(inflater, parent, false)
viewModel.title.observe(lifecycleOwner) { title ->
binding.productNameTv.text = title
}
It’s a bit more code to write but it’s easy to see what is going on there than the magical binding expression.
Byproduct: replacing the deprecated Kotlin Android Extension
When we were replacing data binding with view binding, we also got the chance to remove the Kotlin synthetics from Kotlin Android Extension plugin. This plugin adds extension methods to Activity, Fragments and Views to help you eliminate the calls to findViewById, it’s a plausible concept at the first glance, then you realize what it does under the hood is a dirty hack at best in regards to Android’s lifecycle, there’s little surprise it got deprecated over the years. Unfortunately our project made heavy use of it. With the chance to use view binding, we manage to remove all them.
You can refer to the official documentation to find out how to do it: https://developer.android.com/topic/libraries/view-binding/migration.
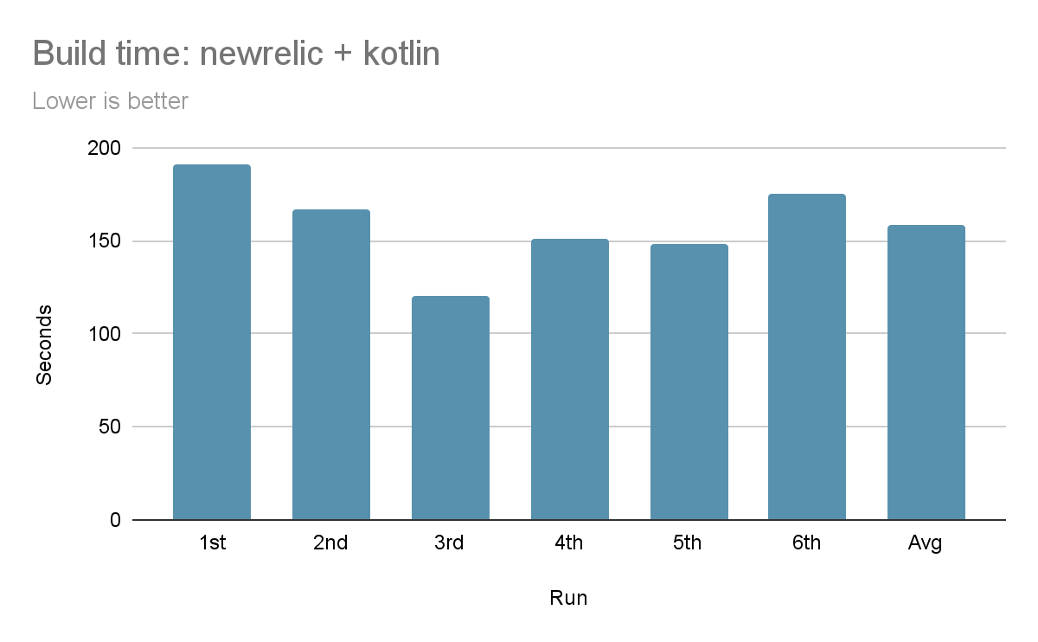
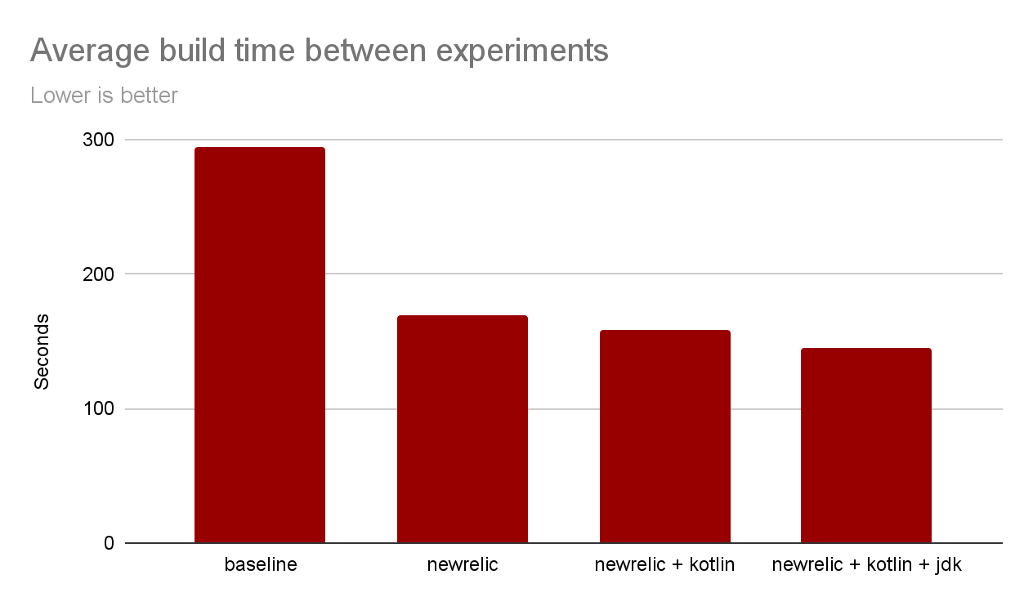
Result
After removing data binding, we are able to migrate our code to use KSP instead. With kapt gone, Kotlin Android Extension gone and ksp enabled, we did another measurement: