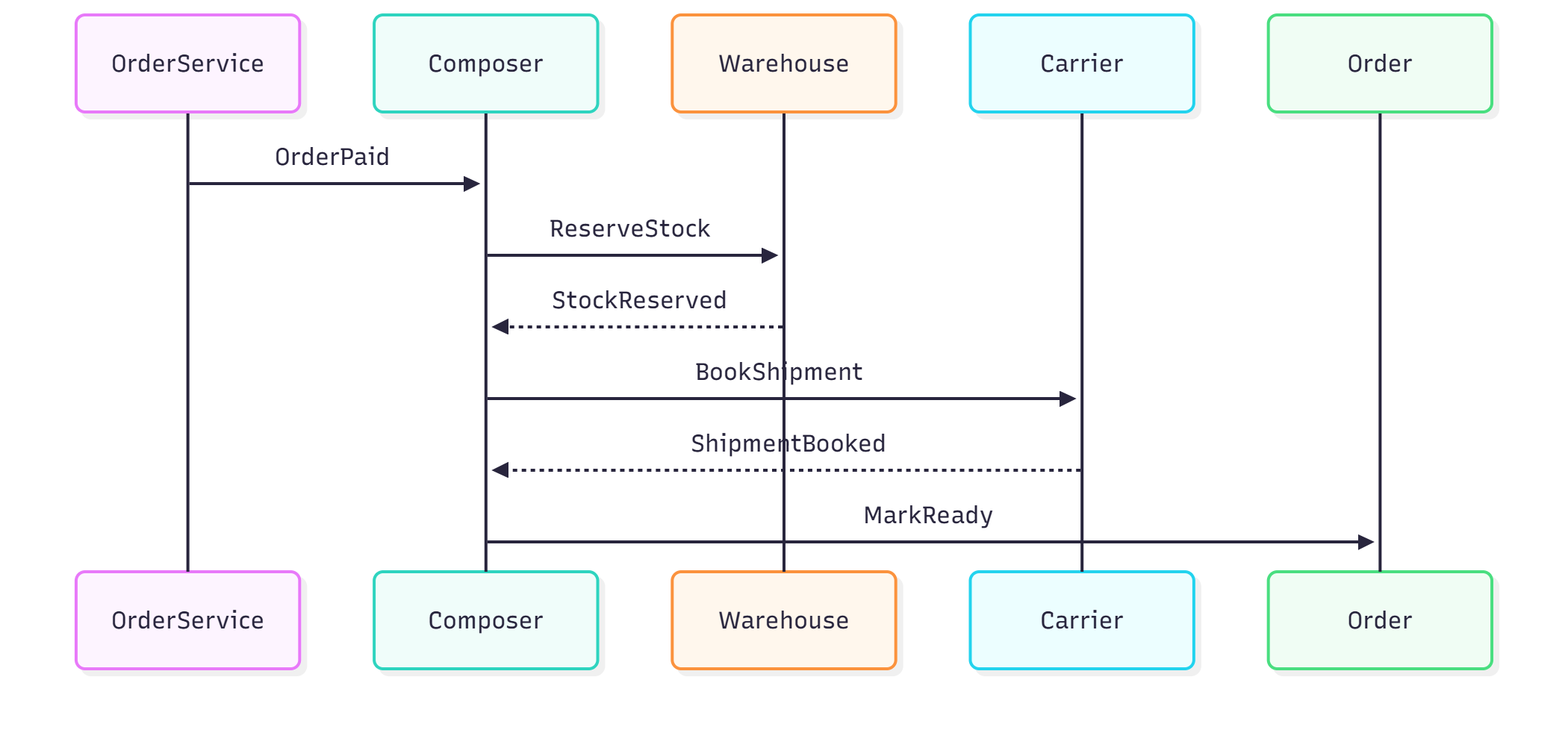
Task scheduling delivers compounding value
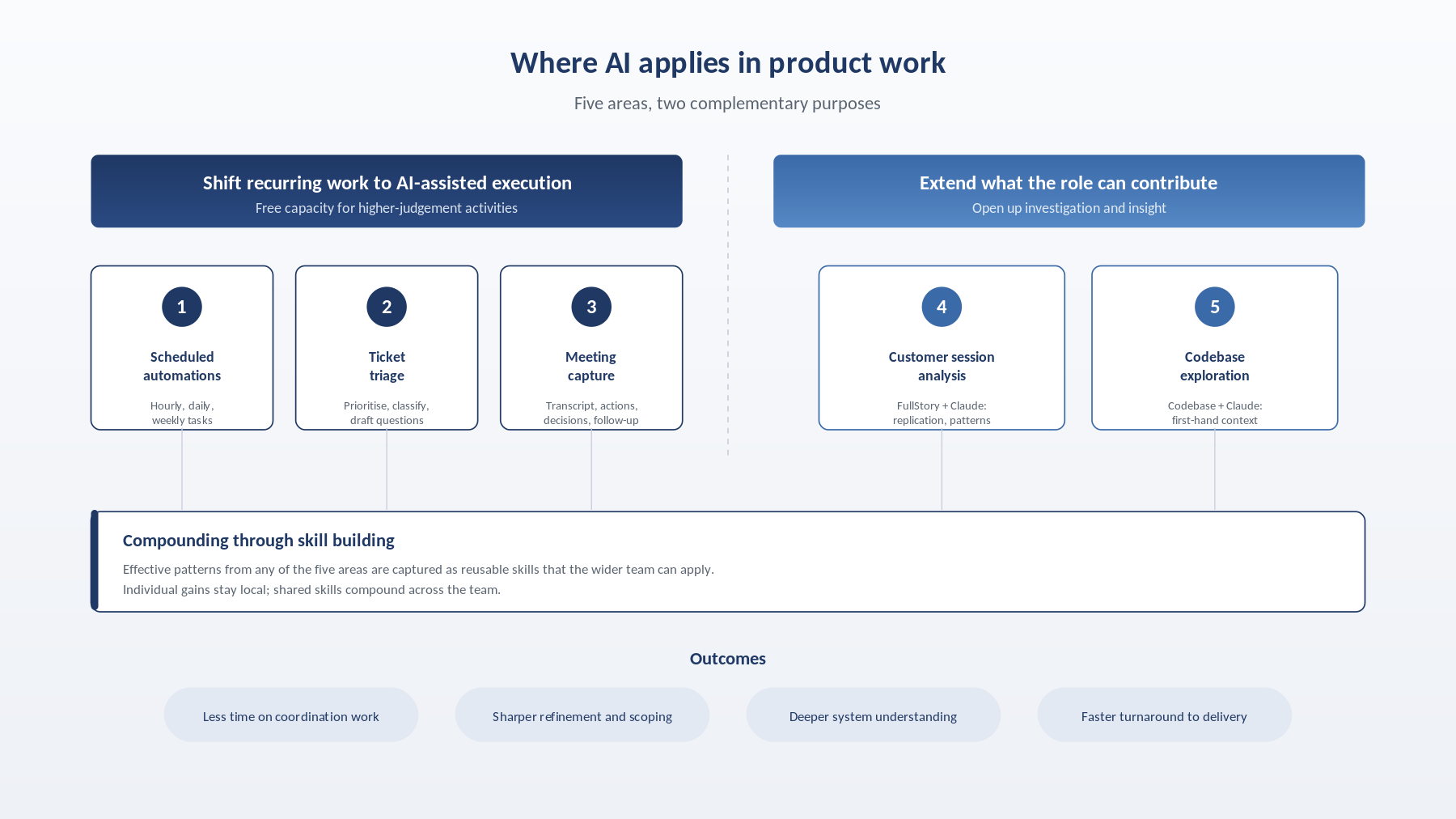
Scheduled tasks are where the return on investment becomes most evident. Once an automation is reliable, it runs quietly in the background and removes an entire category of work from conscious attention. The examples below are some of the tasks I have automated as scheduled tasks via Claude Cowork:
- An hourly Eng Request-to-Jira reminder that runs across the working day, picks up Jira tickets transitioning to LIVE, reads the linked Eng Request context, drafts a stakeholder-ready update, and posts both a Jira comment and a Slack DM with the relevant links.
- A daily ticket triage routine that produces a prioritised view of assigned work, categorises tickets by severity based on thread content, suggests the questions needed to turn feature requests into complete stories, and attempts a lightweight root cause analysis with a proposed fix direction for bugs.
- A weekly squad performance report (covering throughput, cycle time, pipeline state, stale or blocked cards, and delivery highlights), compiled from Jira, Slack, and email, and distributed as a formatted HTML email.
- A Friday wins recap that surfaces the top three squad outcomes by business impact, ensuring delivery is recognised and celebrated.
The value of any single execution is modest. Across dozens of runs a week, the cumulative effect is substantial.
Customer session analysis
When an Engineering Request arrives calling out an issue, the affected FullStory sessions can be opened directly, replication steps reconstructed, and observations recorded as part of triage, compressing the time between a reported problem and a working hypothesis. Beyond individual tickets, sessions can also be surfaced by criteria (a specific feature, an error event, a checkout drop-off point), summarised at speed, and analysed across a cohort rather than individually. Patterns then become directly comparable, moments like rage clicks or form errors are documented in context at the point they are noticed, and the output is written up as a shareable artefact that developers, designers, and QA can respond to.
Meeting notes and action tracking
Capturing a meeting used to mean choosing between engaging with the discussion and keeping a usable record of it. I have been using Granola for this and have found it particularly handy, as it brings the transcript, summarisation notes, and action tracking together in one place, extracting action items with owners and due dates, flagging the decisions made, and drafting the follow-up note ready for review. Full attention can go to the conversation itself.
Connecting Granola to Claude Cowork extends this further. Meeting notes become an input to downstream workflows rather than a standalone record, so the output of one conversation can feed directly into reporting, ticket creation, or stakeholder updates without being manually rekeyed. Drafts are tightened and sent the same day, commitments are visible to everyone who needs them, and actions are less likely to slip through.
Skill building that scales across the team
Where a prompt pattern proves effective (drafting a Jira story from a Slack thread in Kogan’s standard format, generating acceptance criteria from a spike, or refining a squad update), it is worth capturing as a reusable skill. A skill converts one person’s effective workflow into organisational capability, gives colleagues and new joiners a consistent starting point, and reduces ramp-up time. Individual gains matter in isolation; shared skills compound across the team, which is why this is the area most worth investing in at a team level.
Codebase access has been the most significant shift
At Kogan.com, the product team has been granted access to the development repositories, a decision that has proved instrumental. Integrating AI directly with the codebase has been the single largest change in how the role can operate. Through the integration, a deeper, first-hand understanding of how the system actually behaves can be built by querying the codebase directly. For example, it is now possible to ask how Kogan First trial eligibility logic works, what triggers delivery notifications, what types of delivery notifications are sent, or how warehouse prioritisation logic is structured, and to receive substantive answers grounded in the actual source.
It also supports lightweight root cause analysis when a ticket comes through. The goal is not to replace engineering diagnosis, but to arrive at standup with meaningful context rather than open questions. The knock-on effects are a stronger grasp of the system, fewer interruptions for the engineering team, sharper refinement conversations, and faster turnaround from issue to delivery.
Stepping beyond the traditional product remit
On a more personal note, AI has opened a door into work that would previously have sat well outside the scope of the role. Despite my limited practical knowledge in development, I have now implemented a considerable number of tickets, naturally with the support and guidance of my team. Claude Code has been the primary tool for this, with Cursor also used on a few occasions. This has been a small but meaningful step into a new challenge, and one that delivers value to the team as a whole.
Along the way, those tickets have touched practical engineering skills: writing and expanding unit test coverage, resolving merge conflicts, incorporating peer review feedback, and contributing to smaller code reviews. A fuller AI-assisted development cycle is currently in progress, covering epic and card breakdown, estimation, legal change incorporation, and the development work itself.
This is not framed as a recommendation or an expectation for others in product; it is a personal example of how AI can stretch what the role can contribute. The outcome has been twofold: a much deeper understanding of the system, and engineering capacity freed up to focus on genuinely complex work. It has been one of the more rewarding ways AI has reshaped the day, providing a chance to challenge my own limits and learn by doing.
Putting it into practice
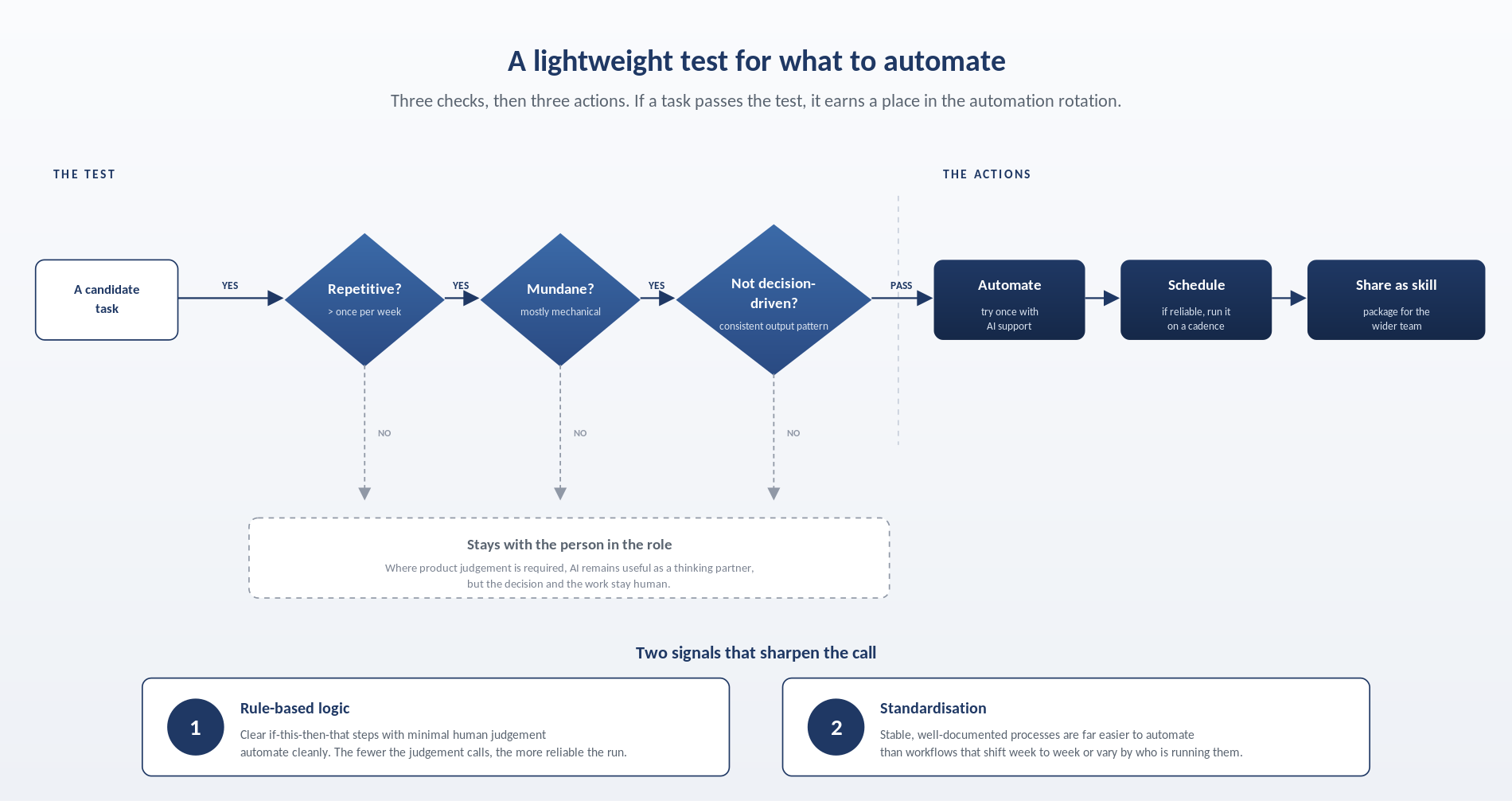
For anyone beginning to explore AI in their own work, a simple starting point is to identify one recent task that felt disproportionately manual. Apply the three-part test. If it qualifies, try it once with AI support. If the output is reliable, schedule it. If it continues to perform, package it as a reusable skill and share it. This loop of trial, schedule, and share is how a team moves from isolated experimentation to embedded practice.
Closing remarks
AI has not displaced what defines the product role: strategy, prioritisation, stakeholder engagement, and the difficult decisions. What it has displaced is much of the friction around that work. For product teams looking to make better use of AI, that is the opportunity worth pursuing. Ultimately, AI delivers a strong starting point rather than a finished product, and every output warrants careful review before it is shared or acted on. Start small, automate the routine, share what works, and let the cumulative effect take hold.